Overview
This post summarizes the approach my teammate Azeez and I used for the 2025 EEG Foundation Challenge (a NeurIPS 2025 competition track), hosted on CodaBench. It opened on 01/09/2025 and ended on 06/10/2025. Our team, "Icarus", finished 84th out of 183 teams (1,181 participants; 8,428 submissions). While we didn't win, we're proud of the ideas we explored and the progress we made. Our code is available on GitHub ![]() .
.
Introduction
Challenges (copy pasted)
Challenge 1 — Cross-Task Transfer Learning. This supervised learning challenge consists of a regression task.
Participants will predict behavioral performance metrics (response time via regression) from an active experimental paradigm (Contrast Change Detection, CCD) using EEG data. We suggest that competitors use passive activities as pretraining and fine-tune into the cognitive task CCD.
We will use our trained model within the competition cluster to make inferences in the CCD set.
Teams can leverage multiple datasets and experimental paradigms to train their models, utilizing unsupervised or self-supervised pretraining to capture latent EEG representations, then fine-tuning for the specific supervised objectives to achieve generalization across subjects and cognitive paradigms. See the Starter Kit for more details.
Note: The initial pretraining design of the SuS task is no longer mandatory because of the high number of participants and the low number of clusters.
Challenge 2 — Externalizing Factor Prediction (Subject Invariant Representation). This supervised regression challenge requires teams to predict four continuous psychopathology scores (externalizing, p-factor, internalizing, and attention) from EEG recordings across multiple experimental paradigms.
Teams can employ unsupervised or self-supervised pretraining strategies to learn generalizable neural representations, then adapt these foundation models for the regression targets while maintaining robustness across different subjects and experimental conditions.
See the Starter Kit for more details. Note: Other factors (internalizing, p-factor, and attention) were removed from the challenge to streamline the execution phase.
Dataset
For model development, the dataset is critical, so we start there. The default training dataset is HBN EEG — Release 5. The leaderboard evaluates using HBN EEG — Release 12, the latest release, which has not been publicly disclosed. According to the organizers, Release 5 is closest in distribution to Release 12. The dataset spans many tasks, including resting state, movie watching, contrast change detection (CCD), the Symbol Search Task (SST), and more. In this competition, we focus on CCD. Here's how we load the dataset:
MINI_RELEASE = True
release_list = ["R5"]
all_datasets_list = [
EEGChallengeDataset(
task="contrastChangeDetection",
release=release,
cache_dir=DATA_DIR,
mini=MINI_RELEASE,
)
for release in release_list
]
Across both sub-challenges, each trial is a 129×200 matrix. Labels differ between the sub-challenges.
Let be the input and the target.
The dataset is cleaned and has been downsampled to 100 Hz from the original 500 Hz. For challenge 1, the data is epoched; . The Bandpass is filtered by (0.5–50 Hz). For full preprocessing details, see eeg2025/downsample-datasets.
Our Methods
Challenge 1 — Response Time from Stimulus
We first visualize the distribution of the response time from stimulus:
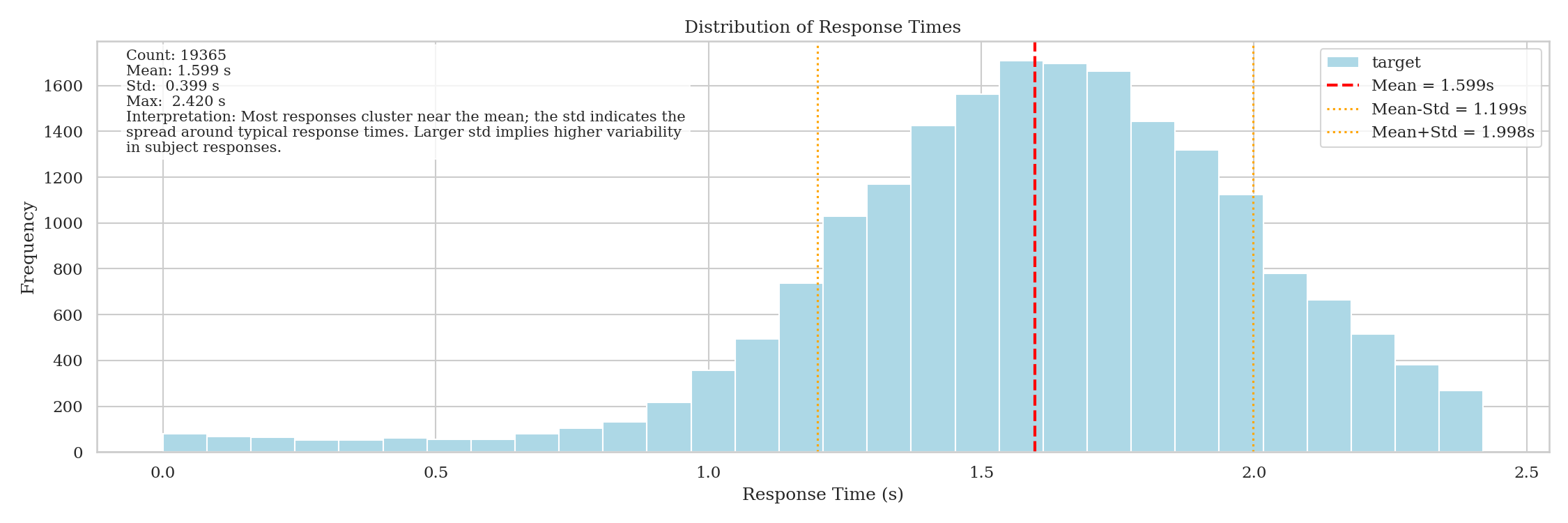
The target is heavily left-skewed. Following common practice, we reflect it and apply a log transformation. The model predicts this transformed value.
The baseline is EEGNeX.
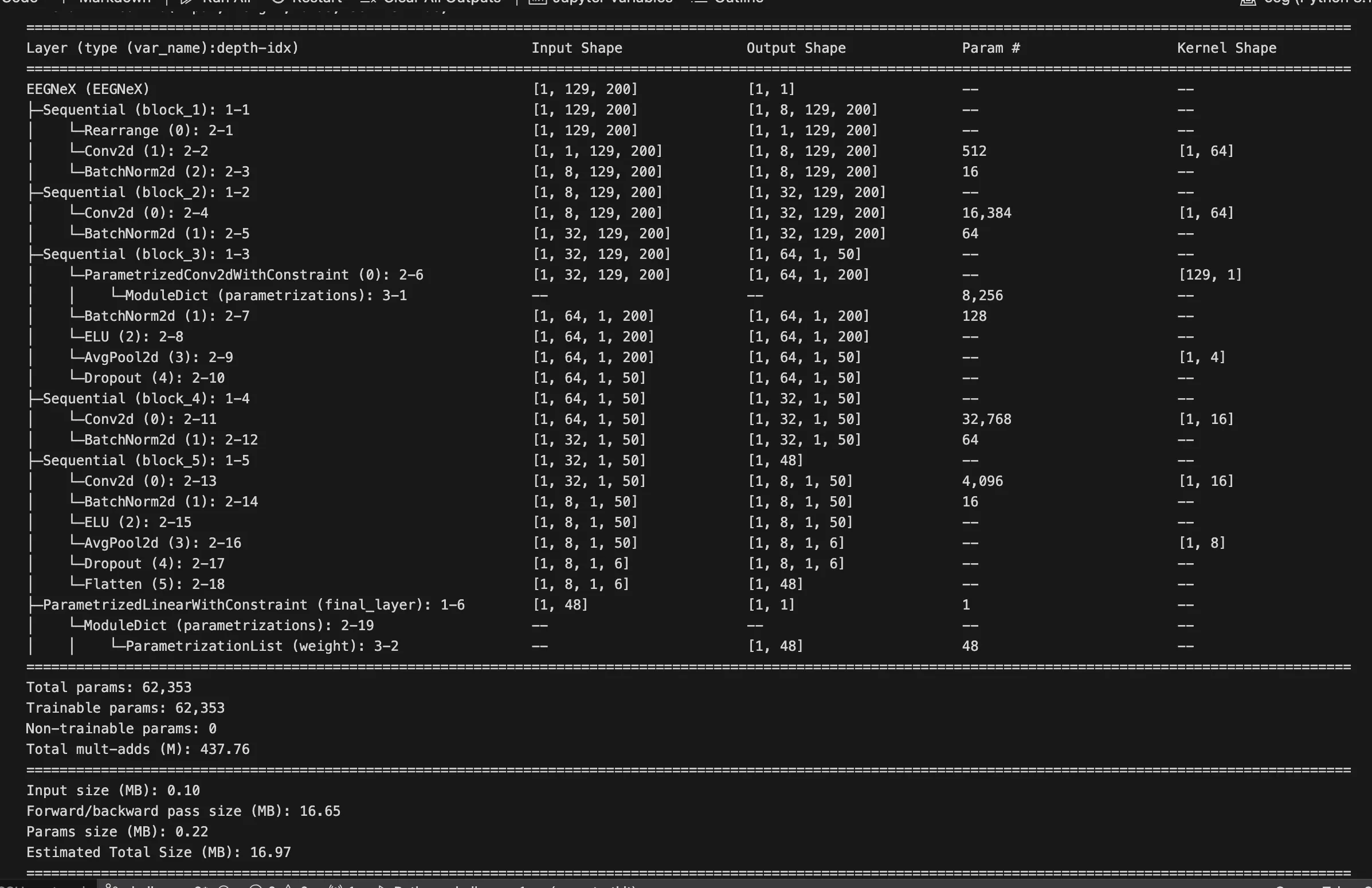
1. Initial Models
As a first step, we tried several models—ResNet, EEGViT, EEGPT, and EEGConformer—in vanilla settings. None outperformed the EEGNeX baseline on this specific challenge. Training loss did not drop below EEGNeX, but the experiments yielded useful insights.
2. Band-Power and PSD Features
The step-1 results suggested that capturing detailed frequency features is key. We therefore adopted a frequency-domain representation. EEG carries sub-band power in delta, theta, alpha, beta, and gamma bands; we apply a Fourier transform to estimate sub-band power and power spectral density (PSD) features using torch.fft.rfft.
# 1) FFT → PSD (Real FFT)
fft_vals = torch.fft.rfft(patches, dim=-1) # (B, P, T//2+1)
psd = (fft_vals ** 2) / T # Power spectral density
3. Patching Module
Inspired by EEG-PatchFormer, we use spatial and temporal patching to capture local and global spatiotemporal dynamics. The original 128 + Cz channels are grouped into 20 custom regions (e.g., “LF-A”, “RT-P”), based on a simple rule-based partition of sensor coordinates to roughly resemble lobes.
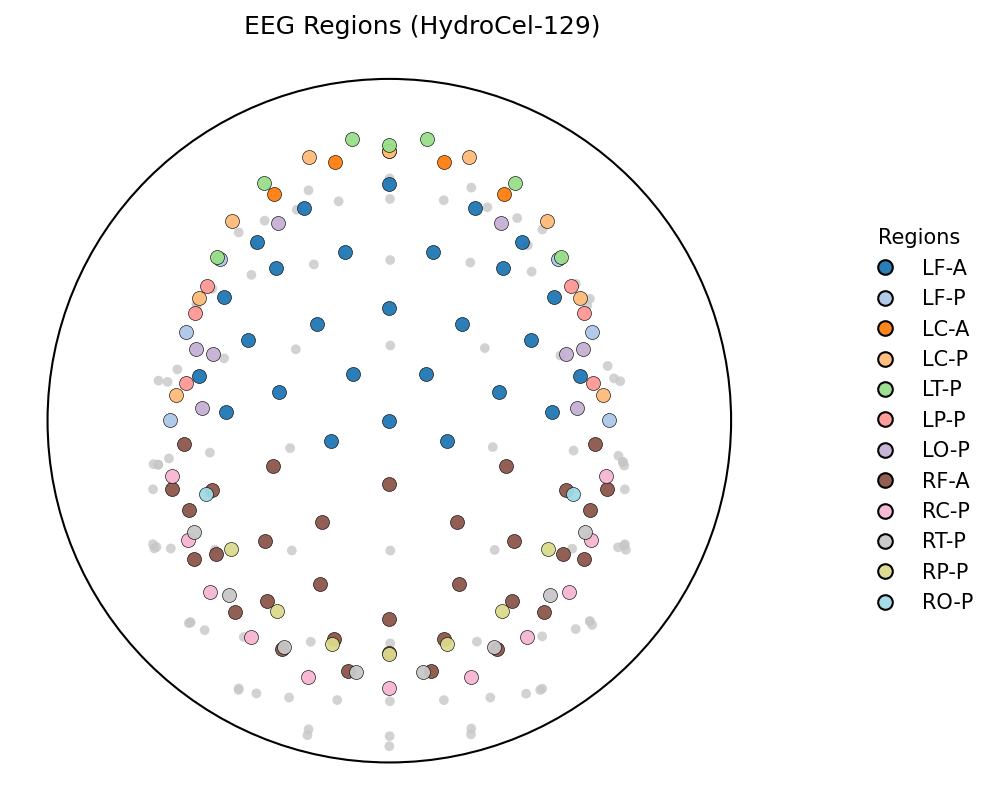
We compute radius , elevation (angle from the +z axis), and azimuth (angle in the x–y plane). Assuming the montage axes line up perfectly:
- If , label as Left.
- If , label as Right.
- → frontal
- → central
- → temporal-ish (T)
- → parietal
- → occipital
4. Architecture
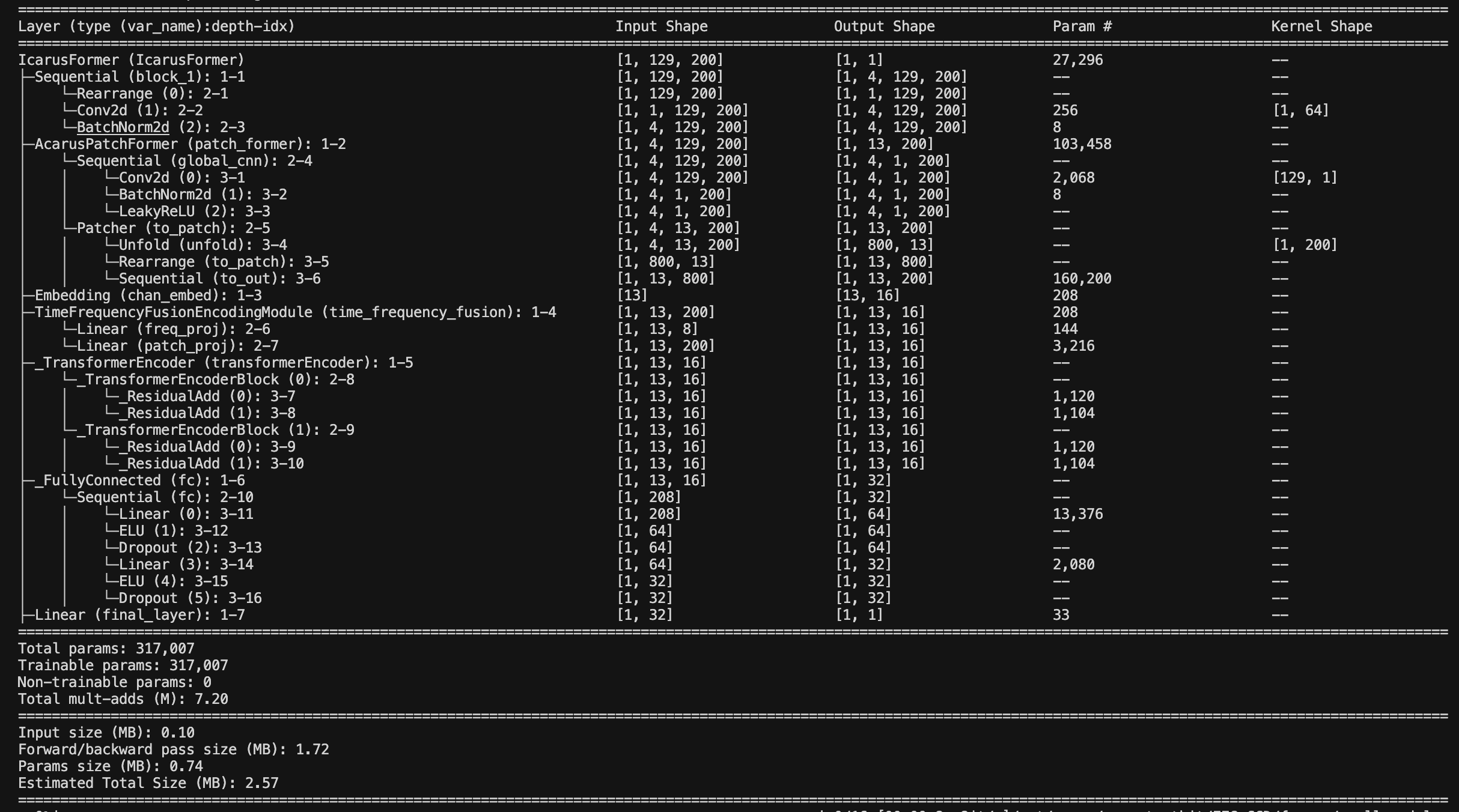
We built the model following the architecture discussed in this review paper. We implement patching, time encoding, and time–frequency fusion. Each EEG patch (a time series) becomes a frequency-aware embedding fused with time-domain and positional embeddings. We call the model IcarusFormer.
Challenge 2 — Externalizing Factor Prediction (Subject-Invariant Representation)
We also visualize the distribution of the externalizing factor:
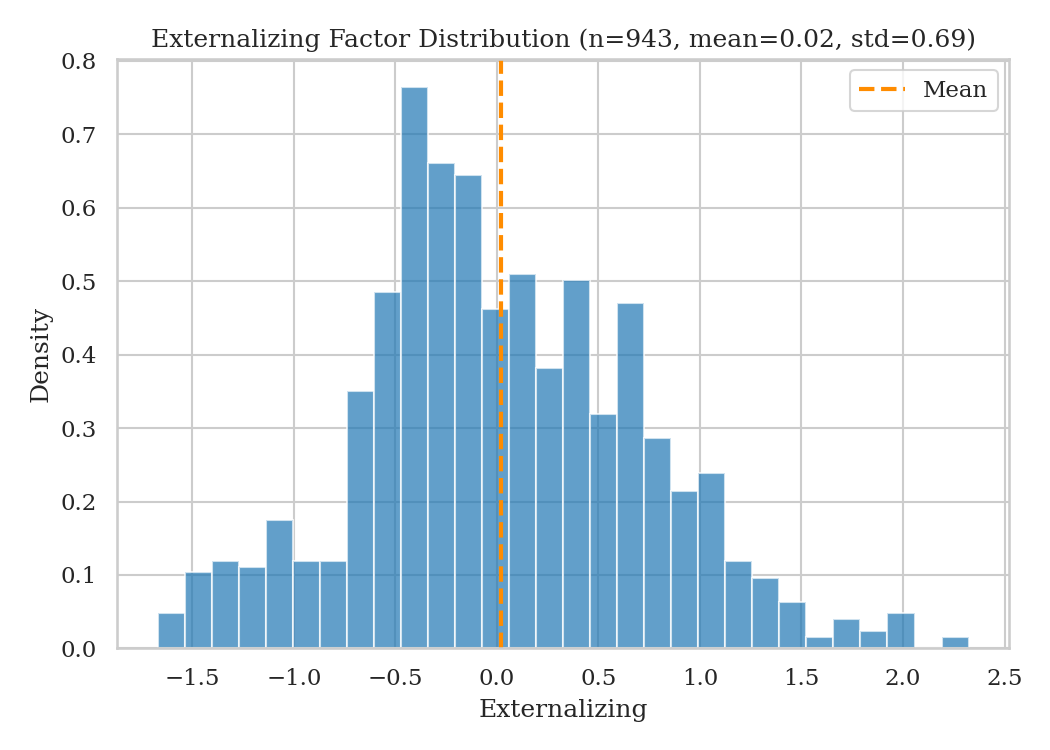
Challenge 2 is harder because there is no easily observable pattern. To tackle it, we used the same model, IcarusFormer, to evaluate its generalization capability. We did not manage to beat the EEGNeX baseline, so we focused more on Challenge 1.
Results
| Models | Lowest Eval RMSE | Test R11 (Mini) RMSE | Test R12 (Full) RMSE/NMRSE (Leaderboard) |
|---|---|---|---|
| EEGNeX | 0.451753 | 0.363023 | 0.4588/1.0001 |
| IcarusFormer | 0.4428 | 0.349423 | 0.4543/0.9903 |
| Models | Lowest Eval RMSE | Test R11 (Mini) RMSE | Test R12 (Full) RMSE (Leaderboard) |
|---|---|---|---|
| EEGNeX | - | 0.603890 | 0.6575/1.0079 |
| IcarusFormer | 0.4428 | 0.597429 | 0.6951/1.0655 |
Analysis
What Went Well and What Didn't
Pros. The clearest improvement came when we adopted the Fourier transform to estimate sub-band power and PSD features. The transformer showed strong spatial modeling potential with inputs of shape (B, N_patches, D).
Cons. Transposing the input (B, N_patches, D) degraded performance. This result contrasts with findings reported for FoME/EEG Foundation Models. Our PatchFormer-style grouping also underperformed, suggesting that simple rule-based grouping is insufficient.
Future Work
There are many gaps to address. Due to time constraints, our code may still contain bugs that need to be identified.
The 129-channel grouping into 20 regions also needs refinement. Rather than relying on our own simple heuristic, we should incorporate groupings informed by prior literature.
Conclusion
We presented a comprehensive approach to the 2025 EEG Foundation Challenge, from dataset loading and preprocessing to model architecture design. Our final rank of 84th out of 183 teams (1,181 participants; 8,428 submissions) reflects the challenges of cross-participant variability and the need for robust, generalizable models in EEG analysis. This journey underscores the importance of feature engineering, careful architectural choices, and rigorous validation in EEG-based machine learning.
References
TBD